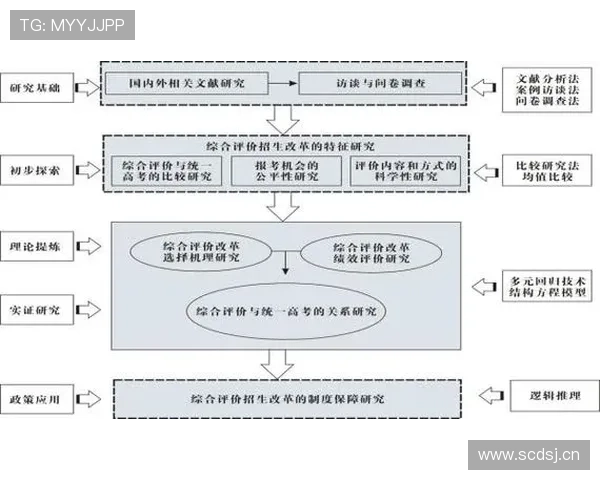
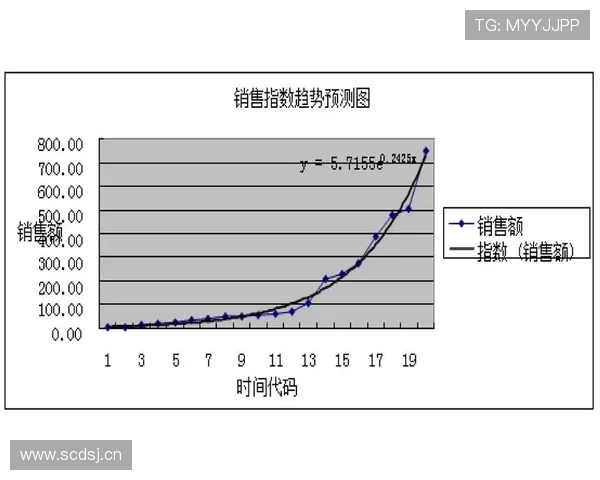
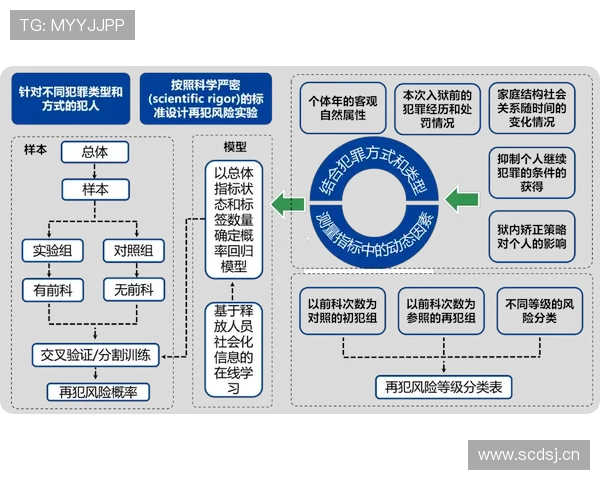
文章摘要:随着大数据、人工智能与计算技术的快速发展,体育竞技分析正从经验驱动逐步迈向多维数据驱动的新阶段。多维数据不仅涵盖运动员个人技术指标、体能状态和心理特征,还延伸至战术执行、环境因素以及赛事历史数据等多个层面,为体育比赛走势分析与胜负预测提供了更加科学、系统的支撑。本文以“多维数据驱动下的体育比赛走势分析与胜负预测研究方法与实践”为核心,从数据基础构建、分析模型方法、实证应用场景以及技术挑战与发展趋势四个方面展开系统阐述,深入探讨多维数据在体育比赛预测中的理论价值与实践意义。通过对不同数据维度的整合分析,揭示体育比赛中隐藏的规律性特征,并结合实际案例说明预测模型在真实赛事中的应用效果。文章旨在为体育数据分析研究者、竞技体育管理者及相关从业人员提供系统性的研究思路与实践参考,推动体育科学与数据智能的深度融合。
多维数据驱动的体育比赛走势分析,首先依赖于科学、系统的数据基础构建。体育数据来源广泛,既包括比赛过程中的技术统计数据,如得分、失误、控球率等,也包括运动员的生理数据、训练负荷数据以及伤病记录等。这些数据共同构成了对比赛和运动员状态的立体刻画,为后续分析提供原始素材。
在数据采集层面,现代体育赛事大量引入传感器、可穿戴设备和视频追踪系统,实现对运动轨迹、速度、加速度等指标的实时记录。相比传统人工统计方式,这种自动化采集手段大幅提升了数据的精度与时效性,使比赛走势分析更加客观可靠。
此外,数据预处理是多维数据基础构建中不可忽视的环节。由于原始数据往往存在噪声、缺失和异构问题,需要通过清洗、标准化和特征提取等方法进行处理。只有在高质量数据基础上,多维数据驱动的走势分析与胜负预测才能具备科学性和可解释性。
在多维数据基础之上,选择合适的数据分析模型是体育比赛走势分析与胜负预测的核心。传统统计模型如回归分析、时间序列分析,能够揭示部分变量之间的线性关系,在早期体育预测研究中发挥了重要作用。
随着机器学习和深度学习技术的发展,非线性模型在体育预测中的应用日益广泛。例如,支持向量机、随机森林和神经网络模型能够处理高维复杂数据,挖掘比赛走势中隐藏的非线性模式,从而提高胜负预测的准确率。
在实践中,往往需要将多种模型进行组合与对比,通过交叉验证和模型融合的方式提升预测稳定性。同时,引入特征重要性分析和可解释性方法,有助于理解模型决策依据,使预测结果不仅“准”,而且“可AC米兰|官方网站信”。
多维数据驱动方法在多种体育项目中已得到广泛应用。以足球比赛为例,通过整合球队历史战绩、球员状态、战术风格以及天气等因素,可以构建综合预测模型,对比赛走势和最终胜负进行概率评估。
在篮球和网球等项目中,数据分析还可以细化到回合级或技术动作级别。通过对进攻效率、防守强度以及关键球表现的分析,研究者能够更准确地判断比赛关键节点,从而预测比赛走向。
实际案例表明,多维数据驱动的预测模型在赛事分析、战术制定和赛前准备中具有显著价值。一些职业俱乐部和体育博彩公司已经将相关模型应用于决策支持系统,提升了竞技表现评估和风险控制能力。
尽管多维数据驱动的体育比赛预测取得了积极进展,但仍面临诸多挑战。一方面,数据隐私与安全问题日益突出,运动员个人数据的合规使用成为研究和实践中必须重视的议题。
另一方面,体育比赛本身具有高度不确定性,突发伤病、临场发挥和心理因素等难以完全量化,这对预测模型的泛化能力提出了更高要求。因此,如何在数据驱动与专业经验之间实现平衡,是未来研究的重要方向。
展望未来,随着人工智能技术的持续进步,多模态数据融合、实时预测以及自适应学习模型将成为发展趋势。多维数据驱动的体育比赛走势分析有望从“辅助决策”迈向“智能协同”,为体育竞技带来更深层次的变革。
总结:
总体而言,多维数据驱动下的体育比赛走势分析与胜负预测,是体育科学与数据智能深度融合的典型体现。通过系统构建数据基础、合理选择分析模型并结合实证应用,可以更加全面地揭示体育比赛的内在规律,为竞技决策提供科学支持。
在未来实践中,随着数据质量提升和技术手段成熟,多维数据驱动方法将在体育赛事分析中发挥更大价值。持续探索方法创新与应用场景拓展,将有助于推动体育预测研究向更加精准、智能和可持续的方向发展。</